2階差のCARモデルを同時密度をつかってStanで実装しようとしてみたが【追記あり】 [統計]
beroberoさんの「[Stan] 久保緑本11章のCAR model(空間構造のあるベイズモデル) 訂正版」では、DAGをつかってCARモデルをStanで実装していましたが、「岩波データサイエンス vol.1」をよんでいるうち、同時密度で実装できないかとおもったので、やってみました。

- 作者:
- 出版社/メーカー: 岩波書店
- 発売日: 2015/10/08
- メディア: 単行本(ソフトカバー)
データは先のブログ記事のgenerate-data.Rのものを使用します。
同時密度の式は「岩波データサイエンス vol.1」の75ページおよび105ページにあります。以下のようなStanコードにしました。
data {
int<lower=1> N;
real Z[N,N];
}
parameters {
real r[N,N];
real<lower=0> s_r;
real<lower=0> s_z;
}
transformed parameters {
vector[N * (N - 2)] u;
vector[N * (N - 2)] v;
real log_prob_r;
// CAR model
for (x in 1:N) {
for (y in 3:N) {
int i;
i <- (x - 1) * (N - 2) + y - 2;
u[i] <- pow((r[x, y] - r[x, y - 1]) - (r[x, y - 1] - r[x, y - 2]), 2);
}
}
for (x in 3:N) {
for (y in 1:N) {
int i;
i <- (x - 3) * N + y;
v[i] <- pow((r[x, y] - r[x - 1, y]) - (r[x - 1, y] - r[x -2, y]), 2);
}
}
log_prob_r <- -(N * N) * log(s_r) +
(-1 / (2 * pow(s_r, 2))) * sum(u) +
(-1 / (2 * pow(s_r, 2))) * sum(v);
}
model {
increment_log_prob(log_prob_r);
for (i in 1:N)
for (j in 1:N)
Z[i, j] ~ normal(r[i, j], s_z);
}
Rコードは以下のようにしました。
library(rstan)
rstan_options(auto_write = TRUE)
options(mc.cores = parallel::detectCores())
inits <- list(list(r = matrix(0.0, ncol = N, nrow = N),
s_r = 0.8, s_z = 1.2),
list(r = matrix(0.4, ncol = N, nrow = N),
s_r = 0.9, s_z = 1.1),
list(r = matrix(0.8, ncol = N, nrow = N),
s_r = 1.0, s_z = 1.0),
list(r = matrix(1.2, ncol = N, nrow = N),
s_r = 1.1, s_z = 0.9))
model2 <- stan_model("CAR_test2.stan")
fit2 <- sampling(model2,
data = list(N = N, Z = Z),
pars = c("r", "s_r", "s_z"),
seed = 1234, init = inits,
iter = 1500, warmup = 500, thin = 1,
open_progress = FALSE)
結果です。
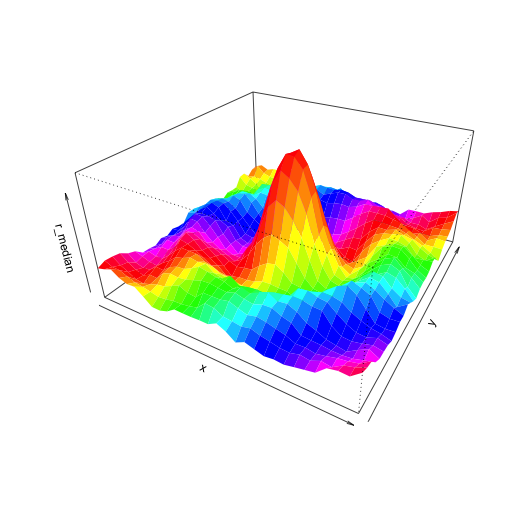
どうもDAGの1階差のCARモデルの結果に似ているようなのですが、はてさて。Full Conditionalでは1階差が2階差になったりするとのことなのですが(「岩波データサイエンス vol.1」102ページ)、なんかまちがえているかもしれません。
[修正] n次 → n階差、に修正しました。
[追記] log_prob_rの計算で定数を省略したのがまずかったかと、下のようにきっちりといれ、rの初期値をZにあわせるとうまくいきました。しかし、rの初期値に適当な値を入れるとやはり収束しません。
log_prob_r <- -(2 * N * (N - 2)) * log(s_r * sqrt(2 * pi())) +
(-1 / (2 * pow(s_r, 2))) * (sum(u) + sum(v));
タグ:STAn




コメント 0