Stanで常微分方程式 [統計]
Stan 2.5では常微分方程式が扱えるようになったということなので、マニュアルを参考にためしてみました。
生態学でつかわれるロジスティック式を解かせてみました。式は以下のようなもの:
![]()
Nは個体数、rは内的増加率、Kは環境収容力(最大個体数)です。
Stanのコードは以下のように。
functions {
real[] logistic(real t,
real[] y,
real[] theta,
real[] x_r,
int[] x_i) {
real dNdt[1];
real r;
real K;
real N;
r <- theta[1];
K <- theta[2];
N <- y[1];
dNdt[1] <- r * N * (K - N) / K;
return dNdt;
}
}
data {
int<lower=1> T;
real N0;
real t0;
real ts[T];
real theta[2]; // r <- theta[1]; K <- theta[2];
}
transformed data {
real x_r[0];
int x_i[0];
}
model {
}
generated quantities {
real y0[1];
real y_hat[T, 1];
y0[1] <- N0;
y_hat <- integrate_ode(logistic, y0, t0, ts, theta, x_r, x_i);
}
最初に微分方程式を関数として定義しています。マニュアルによれば、この関数にあたえる引数は順番に、時間(real)、状態(real[])、パラメーター(real[])、実データ(real[])、整数データ(int[])で、返り値は各時間における状態(real[])ということです。ここでは時間と、実データ・整数データは実際には使っていません。
modelブロックは空で、generated quantitiesブロックで微分方程式を解いています。integrate_ode()にあたえる引数は順番に、微分方程式を記述した関数、初期状態(real[])、初期時間(intまたはreal[])、解を得る時間(real[])、パラメーター(real[])、実データ(real[])、整数データ(int[])となっています。例によって型は厳密です。
Rコードは以下のように。サンプリングはないので、chains = 1, iter = 1としています。
library(rstan)
N0 <- 1 # Initial population size
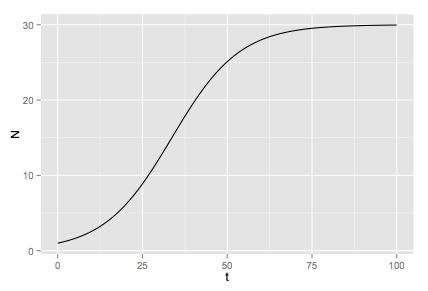
r <- 0.1 # Internal growth rate
K <- 30 # Carrying capacity
t0 <- 0 # Initial time
te <- 100 # Endpoint
intvl <- 0.2 # Interval
t <- seq(t0, te, by = intvl)
fit <- stan(file = "logistic.stan",
data = list(T = length(t) - 1,
N0 = N0,
t0 = t0,
ts = t[-1],
theta = c(r, K)),
chains = 1, iter = 1,
algorithm = "Fixed_param")
# print(fit)
library(ggplot2)
N <- get_posterior_mean(fit)
N <- N[-length(N)]
p <- ggplot(data.frame(t, N))
p + geom_line(aes(x = t, y = N))
結果




コメント 0