自分の歩数データを解析してみる [統計]
歩数計のデータがたまったので、解析みたいなことをしてみた。
データ
- 2009年8月9日から2014年4月30日までの歩数計のカウントデータ
- 「歩いてわかる 生活リズムDS専用生活リズム計」をズボンの左ポケットに入れて計測
- 2012年7月11日は欠測
- データはここにおいておきます。 → url:http://www001.upp.so-net.ne.jp/ito-hi/stat/Hosuu.csv CC-BY-SAにしておきますので、ご自由にご利用ください。
解析
データを読みこむ。
hosuu <- read.csv(url("http://www001.upp.so-net.ne.jp/ito-hi/stat/Hosuu.csv"),
header = FALSE, col.names = c("D", "Y"),
colClasses = c("Date", "numeric"),
comment.char = "#")
まずは平均と標準偏差を求める。
> mean(hosuu$Y, na.rm = TRUE) [1] 10066.68 > sd(hosuu$Y, na.rm = TRUE) [1] 4439.501
あとの解析のため、年, 月, 曜日の列をつくる。年は2009年を1とする。
## 年 hosuu$P <- as.POSIXlt(hosuu$D)[["year"]] hosuu$P <- hosuu$P - min(hosuu$P) + 1 ## 月 hosuu$Q <- as.POSIXlt(hosuu$D)[["mon"]] + 1 ## 曜日 hosuu$R <- as.POSIXlt(hosuu$D)[["wday"]] + 1
グラフを表示する。
library(ggplot2)
gg <- ggplot(hosuu)
gg + geom_line(aes(x = D, y = Y)) +
xlab("年月日") + ylab("歩数") +
theme_bw(base_family = "HiraKakuProN-W3")
gg + geom_histogram(aes(x = Y), binwidth = 1000) +
xlab("歩数") + ylab("頻度") +
theme_bw(base_family = "HiraKakuProN-W3")
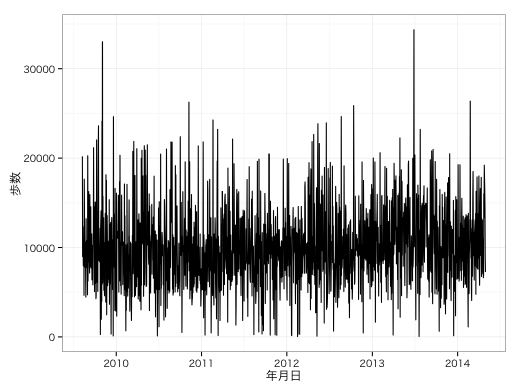
歩数の時系列変化
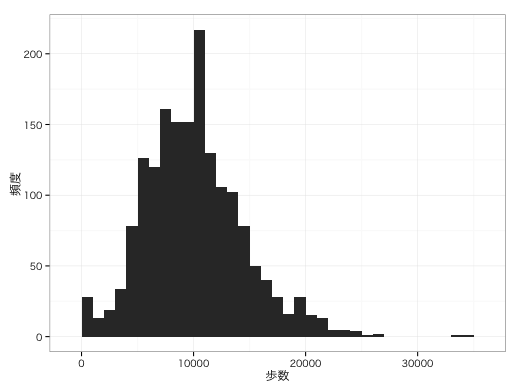
歩数の頻度分布
時系列データなので状態空間モデルで解析しようとしたが、結果はかんばしくなかった。ということで、t=nとt=n+1との関係をプロットしてみる。
ggplot(data.frame(n1 = hosuu[-nrow(hosuu), ]$Y,
n2 = hosuu[-1, ]$Y)) +
geom_point(aes(x = n1, y = n2)) +
xlab("Y[n]") + ylab("Y[n+1]") +
theme_bw()
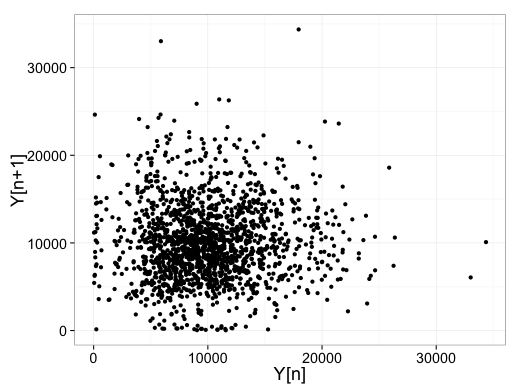
なるほど、t=nとt=n+1はほぼ無相関。自己相関は考えなくてよさそうだ。
ということで、普通に階層モデルで解析。JAGSを使用。カウントデータだが、平均が10000ともなれば正規分布であてはめてもよかろう。
##
## 階層モデル
##
library(rjags)
set.seed(1234)
init.func <- function() {
list(.RNG.name = "base::Mersenne-Twister",
.RNG.seed = rpois(1, 100),
beta = rnorm(1, 10000, 100),
eP = runif(max(hosuu$P), 0, 100),
eQ = runif(12, 0, 100),
eR = runif(7, 0, 100),
sigma = runif(4, 0, 100))
}
model <- jags.model("Hosuu2.bug.txt",
data = list(N = nrow(hosuu), Y = hosuu$Y,
P = hosuu$P, Q = hosuu$Q, R = hosuu$R),
inits = init.func,
n.chains = 4, n.adapt = 3000)
samp <- coda.samples(model,
variable.names = c("beta", "eP", "eQ", "eR", "sigma"),
n.iter = 5000, thin = 5)
BUGSファイルは以下のようなもの
var
N, # データの数
Y[N], # 歩数の観測値
P[N], # 年
Q[N], # 月
R[N], # 曜日
beta, # 歩数の平均
eP[6], # 年のランダム効果
eQ[12], # 月のランダム効果
eR[7], # 曜日のランダム効果
tau[4], # 超パラメーター
sigma[4];
model {
# モデル
for (i in 1:N) {
Y[i] ~ dnorm(beta + eP[P[i]] + eQ[Q[i]] + eR[R[i]], tau[1]);
}
# 事前分布
beta ~ dnorm(10000, 1.0e-6);
for (i in 1:6) {
eP[i] ~ dnorm(0.0, tau[2]);
}
for (i in 1:12) {
eQ[i] ~ dnorm(0.0, tau[3]);
}
for (i in 1:7) {
eR[i] ~ dnorm(0.0, tau[4]);
}
for (i in 1:4) {
tau[i] <- 1 / (sigma[i] * sigma[i]);
sigma[i] ~ dunif(0.0, 1.0e+6);
}
}
収束診断と要約
> gelman.diag(samp)
Potential scale reduction factors:
Point est. Upper C.I.
beta 1.00 1.01
eP[1] 1.00 1.00
eP[2] 1.00 1.00
eP[3] 1.00 1.00
eP[4] 1.00 1.00
eP[5] 1.00 1.01
eP[6] 1.00 1.00
eQ[1] 1.00 1.00
eQ[2] 1.00 1.00
eQ[3] 1.00 1.01
eQ[4] 1.00 1.00
eQ[5] 1.00 1.00
eQ[6] 1.00 1.00
eQ[7] 1.00 1.00
eQ[8] 1.00 1.00
eQ[9] 1.00 1.00
eQ[10] 1.00 1.00
eQ[11] 1.00 1.00
eQ[12] 1.00 1.00
eR[1] 1.00 1.00
eR[2] 1.00 1.01
eR[3] 1.00 1.01
eR[4] 1.01 1.01
eR[5] 1.00 1.00
eR[6] 1.00 1.00
eR[7] 1.00 1.00
sigma[1] 1.00 1.00
sigma[2] 1.01 1.01
sigma[3] 1.00 1.00
sigma[4] 1.00 1.01
Multivariate psrf
1.01
> summary(samp)
Iterations = 3005:8000
Thinning interval = 5
Number of chains = 4
Sample size per chain = 1000
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
beta 10122.95 374.80 5.926 12.946
eP[1] 108.33 426.34 6.741 9.944
eP[2] -448.79 381.04 6.025 11.429
eP[3] -654.85 379.21 5.996 12.493
eP[4] -27.62 376.77 5.957 12.198
eP[5] 663.04 384.98 6.087 11.702
eP[6] 472.31 457.97 7.241 11.626
eQ[1] -178.60 325.22 5.142 5.509
eQ[2] -459.51 346.54 5.479 6.103
eQ[3] -184.11 329.74 5.214 5.675
eQ[4] 886.42 391.39 6.188 7.332
eQ[5] 597.31 366.86 5.800 6.692
eQ[6] 89.33 346.86 5.484 5.259
eQ[7] -111.94 337.80 5.341 5.376
eQ[8] 225.50 330.46 5.225 5.221
eQ[9] -203.78 333.83 5.278 5.703
eQ[10] -39.74 322.03 5.092 5.463
eQ[11] -76.80 327.35 5.176 5.377
eQ[12] -474.72 337.02 5.329 5.872
eR[1] 36.81 163.68 2.588 3.116
eR[2] -79.50 176.73 2.794 3.587
eR[3] 83.28 180.66 2.856 4.451
eR[4] -50.57 168.81 2.669 3.133
eR[5] 44.41 170.69 2.699 3.593
eR[6] 40.14 163.06 2.578 2.971
eR[7] -61.68 174.66 2.762 3.598
sigma[1] 4387.51 75.85 1.199 1.184
sigma[2] 765.03 416.11 6.579 11.088
sigma[3] 557.82 199.40 3.153 4.089
sigma[4] 174.72 151.49 2.395 5.464
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
beta 9355.124 9895.938 10126.20 10356.33 10859.58
eP[1] -736.290 -161.482 106.51 361.20 959.40
eP[2] -1260.128 -675.899 -438.17 -211.17 270.52
eP[3] -1436.384 -882.006 -642.46 -416.94 71.33
eP[4] -771.779 -266.996 -22.47 200.44 722.00
eP[5] -39.143 417.505 645.92 894.08 1458.16
eP[6] -386.576 176.198 451.50 741.34 1437.02
eQ[1] -835.617 -398.985 -161.43 41.00 449.24
eQ[2] -1170.221 -678.573 -442.44 -217.81 177.75
eQ[3] -856.670 -393.436 -172.47 35.65 449.36
eQ[4] 150.190 612.616 873.71 1146.42 1698.63
eQ[5] -59.981 341.132 571.91 838.46 1376.33
eQ[6] -591.461 -137.806 81.98 304.88 808.61
eQ[7] -809.181 -328.755 -105.80 110.18 543.53
eQ[8] -394.216 -1.651 215.11 439.85 910.33
eQ[9] -892.538 -424.298 -195.32 19.19 434.31
eQ[10] -658.635 -251.706 -45.37 173.23 604.07
eQ[11] -732.904 -289.320 -75.46 137.77 562.65
eQ[12] -1172.607 -694.103 -463.48 -237.21 134.10
eR[1] -267.448 -38.098 11.48 98.40 426.02
eR[2] -526.728 -158.063 -36.69 15.65 204.63
eR[3] -187.759 -11.021 36.37 153.17 534.11
eR[4] -445.385 -124.175 -20.94 27.18 263.11
eR[5] -268.138 -34.817 16.48 113.57 433.69
eR[6] -261.901 -37.242 13.34 106.97 459.93
eR[7] -489.514 -135.480 -24.17 22.63 245.43
sigma[1] 4239.466 4335.347 4387.06 4439.11 4532.80
sigma[2] 297.864 507.859 666.99 899.12 1853.09
sigma[3] 227.749 422.268 532.54 662.11 1020.40
sigma[4] 6.414 62.248 137.14 240.75 564.46
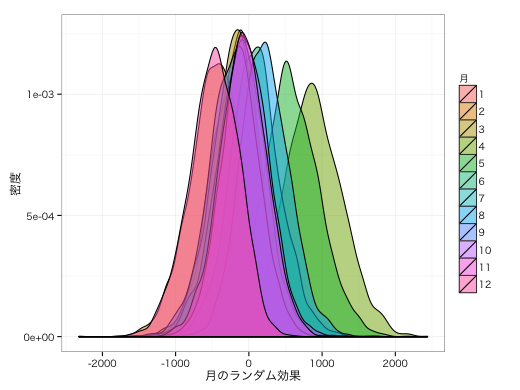
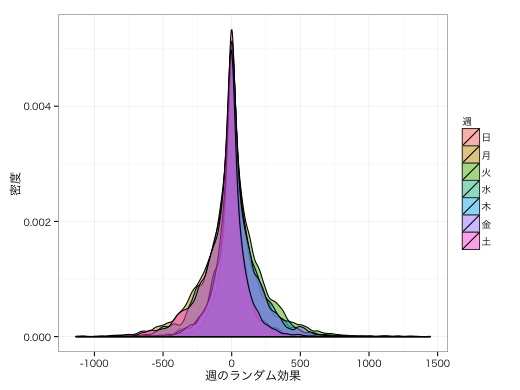
2010〜2011年ごろはあまり歩いていない。一方、2013〜2014年はよく歩いている。 月別でいうと、12〜3月はあまり歩いていない。一方、4〜5月はよく歩いている。 曜日による変動はあまり大きくない。
ランダム効果をグラフを表示
n.samples <- niter(samp) * nchain(samp)
pos.eP1 <- match("eP[1]", varnames(samp))
range.eP <- pos.eP1:(pos.eP1 + max(hosuu$P) - 1)
pos.eQ1 <- match("eQ[1]", varnames(samp))
range.eQ <- pos.eQ1:(pos.eQ1 + 11)
pos.eR1 <- match("eR[1]", varnames(samp))
range.eR <- pos.eR1:(pos.eR1 + 6)
eP <- data.frame(x = c(sapply(range.eP,
function(i) unlist(samp[, i]))),
v = as.factor(rep(2009:2014, each = n.samples)))
eQ <- data.frame(x = c(sapply(range.eQ,
function(i) unlist(samp[, i]))),
v = as.factor(rep(1:12, each = n.samples)))
youbi <- c("日", "月", "火", "水", "木", "金", "土")
eR <- data.frame(x = c(sapply(range.eR,
function(i) unlist(samp[, i]))),
v = factor(rep(youbi, each = n.samples), levels = youbi))
##
library(ggplot2)
ggplot(eP) + geom_density(aes(x = x, fill = v), alpha = 0.5) +
labs(fill = "年", x = "年のランダム効果", y = "密度") +
theme_bw(base_family = "HiraKakuProN-W3")
ggplot(eQ) + geom_density(aes(x = x, fill = v), alpha = 0.5) +
labs(fill = "月", x = "月のランダム効果", y = "密度") +
theme_bw(base_family = "HiraKakuProN-W3")
ggplot(eR) + geom_density(aes(x = x, fill = v), alpha = 0.5) +
labs(fill = "週", x = "週のランダム効果", y = "密度") +
theme_bw(base_family = "HiraKakuProN-W3")
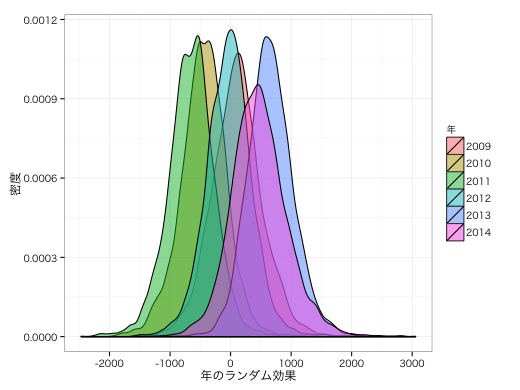
あと、天気とかを説明変数にいれるとよいような気がするが、いまとなってはもうわからない。過去の所在地はもうよくわからないので。




コメント 0