年輪データの状態空間モデルへのあてはめ [統計]
手もとにあった、年輪データ(コナラ31本、1970〜2009年、法政大学多摩校地で採取)をStanで状態空間モデルにあてはめてみた。
なお、状態空間モデルで年輪データを解析した例は、Shimatani and Kubota (2011)などがある。
Stanのモデル: Nenrin2.stan
data {
int<lower=0> N; // number of years
int<lower=0> M; // number of trees
real<lower=0> Y[N, M]; // ring width
int<lower=1> P[M]; // plot
int<lower=0> Np; // number of plots
}
parameters {
real mu[N];
real beta[N, M];
real ep[Np];
real<lower=0> sigma[5];
}
model {
// observation
for (t in 1:N) {
for (i in 1:M) {
log(Y[t, i]) ~ normal(mu[t] + beta[t, i] + ep[P[i]], sigma[1]);
}
}
// system
for (t in 2:N) {
mu[t] ~ normal(mu[t - 1], sigma[2]);
for (i in 1:M) {
beta[t, i] ~ normal(beta[t - 1, i], sigma[3]);
}
}
mu[1] ~ normal(0, 1.0e+3);
for (i in 1:M) {
beta[1, i] ~ normal(0, sigma[4]);
}
for (i in 1:Np) {
ep[i] ~ normal(0, sigma[5]);
}
for (i in 1:5) {
sigma[i] ~ uniform(0, 1.0e+4);
}
}
CmdStanで並列実行。データは、Nenrin2_dump.Rにdump()で出力しておく。計算はわりとすぐおわる。
#!/bin/sh
WARMUP=1000
ITER=10000
THIN=10
REFRESH=1000
./Nenrin2 sample num_samples=${ITER} num_warmup=${WARMUP} thin=${THIN} \
id=1 data file=Nenrin2_dump.R random seed=123 \
output file=Nenrin2_chain1.csv refresh=${REFRESH} &
./Nenrin2 sample num_samples=${ITER} num_warmup=${WARMUP} thin=${THIN} \
id=2 data file=Nenrin2_dump.R random seed=1234 \
output file=Nenrin2_chain2.csv refresh=${REFRESH} &
./Nenrin2 sample num_samples=${ITER} num_warmup=${WARMUP} thin=${THIN} \
id=3 data file=Nenrin2_dump.R random seed=12356 \
output file=Nenrin2_chain3.csv refresh=${REFRESH} &
./Nenrin2 sample num_samples=${ITER} num_warmup=${WARMUP} thin=${THIN} \
id=4 data file=Nenrin2_dump.R random seed=123567 \
output file=Nenrin2_chain4.csv refresh=${REFRESH}
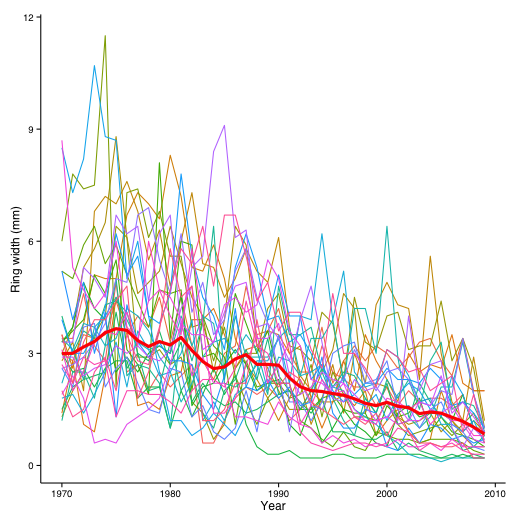
結果をグラフ化
library(coda)
samp <- lapply(1:4,
function(i) {
filename <- paste("Nenrin2_chain", i, ".csv", sep = "")
mcmc(read.csv(filename, comment = "#"),
start = 1001, end = 10000, thin = 10)
})
samp <- as.mcmc.list(samp)
## convergence diagnostics
gelman.diag(samp, multivariate = FALSE)
## summary
summ <- summary(samp)
par.names <- rownames(summ$statistics)
pos.mu1 <- match("mu.1", par.names)
pos.mu40 <- match("mu.40", par.names)
mu <- summ$statistics[pos.mu1:pos.mu40, "Mean"]
## read original data
source("Nenrin2_dump.R")
data <- data.frame(Y)
data$year <- 1970:2009
## graph
library(ggplot2)
library(reshape)
data <- melt(data, id = "year")
data.mu <- data.frame(year = 1970:2009, exp.mu = exp(mu))
plt <- ggplot(data)
plt + geom_line(aes(year, value, group = variable, colour = variable)) +
geom_line(aes(year, exp.mu), data = data.mu, colour = "red",
size = 1.5) +
xlab("Year") + ylab("Ring width (mm)") +
theme_classic(12, "Helvetica") +
theme(legend.position = "none")
グラフ




コメント 0