R: lavaanでSEM [統計]
semパッケージが激しく進化!version3になり超実用的に - はやしのブログ Rev.3という1年ばかり前のブログ記事をよんで、なぜかlavaanをためしてみるテスト。
- The lavaan Project
- Rosseel, Y (2012) lavaan: An R Package for Structural Equation Modeling. Journal of Statistical Software 48(2).
まずはむかしやったことのあるパス解析から。狩野・三浦(2002) p.20より。モデルは下の図。

# 価格
kakaku <- c(89, 99, 128, 98, 52, 47,
40, 39, 38, 48, 27, 23)
# 走行距離
kyori <- c(4.3, 1.9, 5.2, 5.1, 4.0, 4.8,
8.7, 8.2, 3.3, 3.9, 8.2, 7.2)
# 乗車年数
nensuu <- c(5, 4, 2, 3, 6, 8,
7, 7, 10, 6, 8, 8)
# 車検
syaken <- c(24, 18, 13, 4, 15, 24,
3, 6, 14, 0, 24, 24)
data <- data.frame(kakaku, kyori, nensuu, syaken)
## lavaan
library(lavaan)
model.text <- "
kakaku ~ nensuu + syaken + kyori
kyori ~ nensuu
"
fit <- sem(model.text, data = data)
結果
> summary(fit)
lavaan (0.5-13) converged normally after 33 iterations
Number of observations 12
Estimator ML
Minimum Function Test Statistic 0.380
Degrees of freedom 1
P-value (Chi-square) 0.538
Parameter estimates:
Information Expected
Standard Errors Standard
Estimate Std.err Z-value P(>|z|)
Regressions:
kakaku ~
nensuu -12.672 1.428 -8.873 0.000
syaken 0.401 0.354 1.130 0.258
kyori -3.612 1.481 -2.439 0.015
kyori ~
nensuu 0.260 0.260 1.000 0.317
Variances:
kakaku 106.073 43.304
kyori 4.029 1.645
standardized = TRUEとすると標準解を表示する。
> summary(fit, standardized = TRUE)
lavaan (0.5-13) converged normally after 33 iterations
Number of observations 12
Estimator ML
Minimum Function Test Statistic 0.380
Degrees of freedom 1
P-value (Chi-square) 0.538
Parameter estimates:
Information Expected
Standard Errors Standard
Estimate Std.err Z-value P(>|z|) Std.lv Std.all
Regressions:
kakaku ~
nensuu -12.672 1.428 -8.873 0.000 -12.672 -0.876
syaken 0.401 0.354 1.130 0.258 0.401 0.107
kyori -3.612 1.481 -2.439 0.015 -3.612 -0.234
kyori ~
nensuu 0.260 0.260 1.000 0.317 0.260 0.277
Variances:
kakaku 106.073 43.304 106.073 0.102
kyori 4.029 1.645 4.029 0.923
Std.lvは潜在変数のみの分散を、Std.allは潜在変数と観測変数の両方の分散を、それぞれ標準化したときの値ということである。
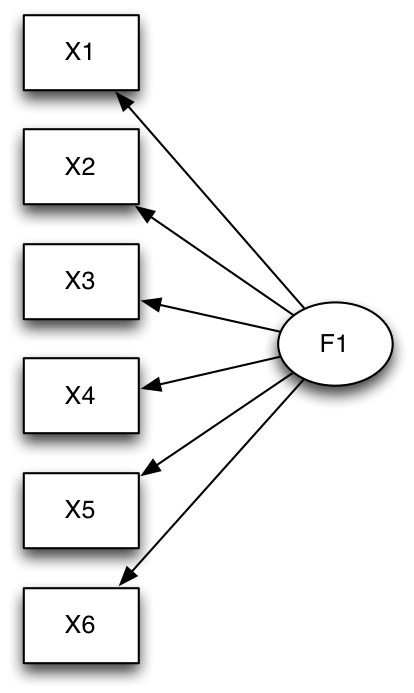
つづいて、これも昔やった因子分析。狩野・三浦(2002) p.74より。
model 1
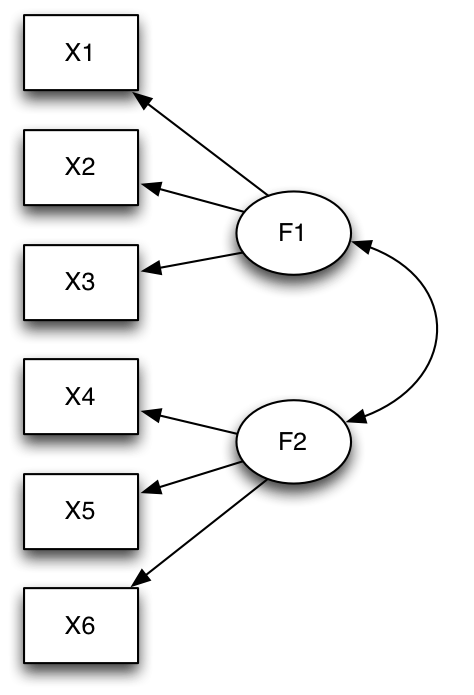
model 2
n <- 220
R <- readMoments(diag = FALSE,
names = c("X1", "X2", "X3", "X4", "X5", "X6"))
0.439
0.410 0.351
0.288 0.354 0.164
0.329 0.320 0.190 0.595
0.248 0.329 0.181 0.470 0.484
## lavaan
model1 <- "
F1 =~ X1 + X2 + X3 + X4 + X5 + X6
"
fit.model1 <- sem(model1, sample.cov = R, sample.nobs = n)
model2 <- "
F1 =~ X1 + X2 + X3
F2 =~ X4 + X5 + X6
F1 ~~ F2
"
fit.model2 <- sem(model2, sample.cov = R, sample.nobs = n)
結果
> summary(fit.model1, standardized = TRUE) lavaan (0.5-13) converged normally after 26 iterations Number of observations 220 Estimator ML Minimum Function Test Statistic 53.488 Degrees of freedom 9 P-value (Chi-square) 0.000 Parameter estimates: Information Expected Standard Errors Standard Estimate Std.err Z-value P(>|z|) Std.lv Std.all Latent variables: F1 =~ X1 1.000 0.489 0.490 X2 1.085 0.200 5.417 0.000 0.531 0.532 X3 0.703 0.175 4.018 0.000 0.344 0.345 X4 1.486 0.236 6.298 0.000 0.727 0.729 X5 1.513 0.239 6.334 0.000 0.741 0.742 X6 1.275 0.216 5.910 0.000 0.624 0.626 Variances: X1 0.756 0.079 0.756 0.759 X2 0.714 0.076 0.714 0.717 X3 0.877 0.087 0.877 0.881 X4 0.467 0.065 0.467 0.469 X5 0.447 0.064 0.447 0.449 X6 0.606 0.070 0.606 0.609 F1 0.239 0.069 1.000 1.000 > AIC(fit.model1) [1] 3497.724 > summary(fit.model2, standardized = TRUE) lavaan (0.5-13) converged normally after 24 iterations Number of observations 220 Estimator ML Minimum Function Test Statistic 7.820 Degrees of freedom 8 P-value (Chi-square) 0.451 Parameter estimates: Information Expected Standard Errors Standard Estimate Std.err Z-value P(>|z|) Std.lv Std.all Latent variables: F1 =~ X1 1.000 0.686 0.688 X2 0.976 0.152 6.422 0.000 0.670 0.671 X3 0.775 0.133 5.811 0.000 0.532 0.533 F2 =~ X4 1.000 0.755 0.757 X5 1.029 0.117 8.809 0.000 0.777 0.779 X6 0.829 0.104 7.950 0.000 0.626 0.627 Covariances: F1 ~~ F2 0.308 0.061 5.044 0.000 0.595 0.595 Variances: X1 0.525 0.082 0.525 0.527 X2 0.547 0.081 0.547 0.549 X3 0.713 0.081 0.713 0.716 X4 0.425 0.067 0.425 0.427 X5 0.391 0.067 0.391 0.393 X6 0.604 0.070 0.604 0.606 F1 0.471 0.103 1.000 1.000 F2 0.570 0.101 1.000 1.000 > AIC(fit.model2) [1] 3454.056

グラフィカル多変量解析―AMOS、EQS、CALISによる 目で見る共分散構造分析
- 作者: 狩野 裕
- 出版社/メーカー: 現代数学社
- 発売日: 2002/06
- メディア: 単行本




コメント 0