R: Stanをためす (2) [統計]
久保本10章の個体差+場所差モデルをやってみる。
kubo10b.stan
// Kubo Book 10.5
data {
int<lower=0> N_sample; // number of observations
int<lower=0> N_pot; // number of pots
int<lower=0> N_sigma; // number of sigmas
int<lower=0> Y[N_sample]; // number of seeds
int<lower=0> F[N_sample]; // fertilizer
int<lower=0> Pot[N_sample]; // pot
}
parameters {
real beta1;
real beta2;
real r[N_sample];
real rp[N_pot];
real<lower=0> sigma[N_sigma];
}
transformed parameters {
real<lower=0> lambda[N_sample];
for (i in 1:N_sample) {
lambda[i] <- exp(beta1 + beta2 * F[i] + r[i] + rp[Pot[i]]);
}
}
model {
for (i in 1:N_sample) {
Y[i] ~ poisson(lambda[i]);
}
beta1 ~ normal(0, 100);
beta2 ~ normal(0, 100);
r ~ normal(0, sigma[1]);
rp ~ normal(0, sigma[2]);
for (k in 1:N_sigma) {
sigma[k] ~ uniform(0, 1.0e+4);
}
}
kubo10b.R
## Kubo Book Chapter 10 Section 10.5
library(coda)
library(parallel)
program <- "kubo10b"
# read data
d <- read.csv(url("http://hosho.ees.hokudai.ac.jp/~kubo/stat/iwanamibook/fig/hbm/nested/d1.csv"))
N_sample <- nrow(d)
N_pot <- length(levels(d$pot))
N_sigma <- 2
Y <- d$y
F <- as.numeric(d$f == "T")
Pot <- as.numeric(d$pot)
# dump data
data.file <- paste(program, "Rdump", sep = ".")
dump(c("N_sample", "N_pot", "N_sigma", "Y", "F", "Pot"), data.file)
# Stan
stan.home <- ("~/Documents/src/stan-src-1.0.0")
cur.dir <- getwd()
setwd(stan.home)
system(paste("make ", cur.dir, "/", program, sep = ""))
setwd(cur.dir)
run <- function(chain, seed) {
cmd <- paste("./", program,
" --data=", data.file,
" --iter=51000 --warmup=1000 --thin=50",
" --seed=", seed,
" --chain_id=", chain,
" --samples=", program, ".chain", chain, ".csv", sep = "")
system(cmd)
s <- read.csv(paste(program, ".chain", chain, ".csv", sep = ""), comment.char = "#")
mcmc(s, start = 1001, thin = 50)
}
seeds <- c(1234, 12345, 123456)
samples <- as.mcmc.list(mclapply(1:3, function(i) run(i, seeds[i]), mc.cores = 4))
plot(samples[, c("beta1", "beta2", "sigma.1", "sigma.2")])
summary(samples[, c("beta1", "beta2", "sigma.1", "sigma.2")])
結果
> plot(samples[, c("beta1", "beta2", "sigma.1", "sigma.2")])
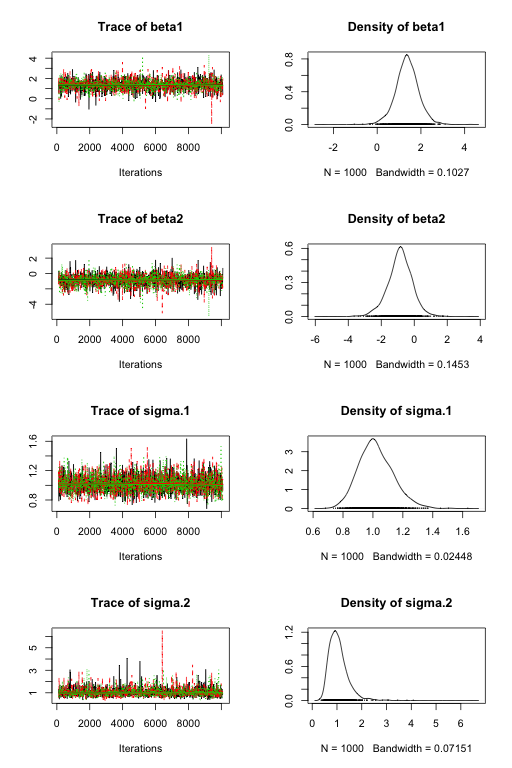
> summary(samples[, c("beta1", "beta2", "sigma.1", "sigma.2")])
Iterations = 101:10091
Thinning interval = 10
Number of chains = 3
Sample size per chain = 1000
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
beta1 1.3681 0.5335 0.009741 0.009811
beta2 -0.8649 0.7552 0.013787 0.014276
sigma.1 1.0208 0.1160 0.002117 0.001840
sigma.2 1.0565 0.4002 0.007306 0.007201
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
beta1 0.2709 1.0470 1.3660 1.6908 2.4105
beta2 -2.4516 -1.3026 -0.8421 -0.3915 0.5794
sigma.1 0.8159 0.9395 1.0111 1.0930 1.2709
sigma.2 0.5291 0.7853 0.9901 1.2336 1.9913




先生のサンプルをもとに、自分でもStanを動かしてみたところ、
2 warnings generated.
Error in data_preprocess(data) : duplicated names in data list:
failed to preprocess the data; sampling not done
というエラーがでて「fit <- stan(file="kubo10b.stan", data=dat, iter=1000,chains=4)」が実行できませんでした。
どうしてこうなるのか、理由をご存知でしたらご教示いただけませんでしょうか。
by 前橋健太郎 (2015-04-04 23:52)
dat中の名前が重複していませんか?
by hiroki (2015-04-05 07:56)
先生、ご返信ありがとうございます。エラーメッセージだけ読むと、私もそう思ったのですが、datの中を読む限り、名前が重複しているようには思えないのです。
お手数ですが、以下のコードをお読みいただけませんでしょうか。
d <- read.csv(url("http://hosho.ees.hokudai.ac.jp/~kubo/stat/iwanamibook/fig/hbm/nested/d1.csv"))
dat <- list(N_sample = 100, #nrow(d)
N_pot = 10,
N_sigma = 2,
Y <- d$y,
F <- as.numeric(d$f == "T"),
Pot <- as.numeric(d$pot) )
fit <- stan(file="kubo10b.stan", data=dat, iter=1000,chains=4)
by 前橋健太郎 (2015-04-05 11:46)
Y, F, Potのところですが、"<-" ではなくて、 "="ですね。
by hiroki (2015-04-05 12:07)
先生、ついRの他の箇所と同じように入力しておりました。
今直して動かしたところ、無事動きました。
お忙しい中お時間をとっていただき、ありがとうございました。
by 前橋健太郎 (2015-04-05 13:55)