累積ロジットモデルのベイズ推定 [統計]
以前vglmで解析したデータをベイズ推定で解析してみた。nプロットについて、ある植物の被度(c1)を5段階で計測するというような場合を想定。被度は傾斜(slope)が急になるほど減るとする。
set.seed(123) n <- 30 n.rank <- 5 slope <- rgamma(n, shape = 15^2/5^2, rate = 15/5^2) logit.c1 <- 7.5 - 0.5 * slope + rnorm(n, 0, 1) c1 <- rbinom(n, n.rank - 1, exp(logit.c1)/(1 + exp(logit.c1))) + 1
c1の累積値を格納する行列としてcumを用意。
cum <- matrix(NA, nrow = n, ncol = n.rank - 1) cum[,1] <- as.numeric(c1 >= 2) cum[,2] <- as.numeric(c1 >= 3) cum[,3] <- as.numeric(c1 >= 4) cum[,4] <- as.numeric(c1 >= 5)
BUGSコードを用意。cumlogit_MCMC.bugというファイル名で保存しておく。
var
N,
M,
beta,
b[M],
c[N, M],
s[N];
model {
for (j in 1:M) {
for (i in 1:N) {
c[i, j] ~ dbern(p[i, j]);
logit(p[i, j]) <- b[j] + beta * s[i];
}
b[j] ~ dnorm(0.0, 1.0E-4);
}
beta ~ dnorm(0.0, 1.0E-4);
}
rjagsを使用。
library(rjags)
model <- jags.model("cumlogit_MCMC.bug",
data = list(N = n, M = n.rank - 1,
s = slope, c = cum),
nchain = 3, n.adapt = 10000)
post <- coda.samples(model,
variable = c("b", "beta"),
n.iter = 20000, thin = 20)
結果
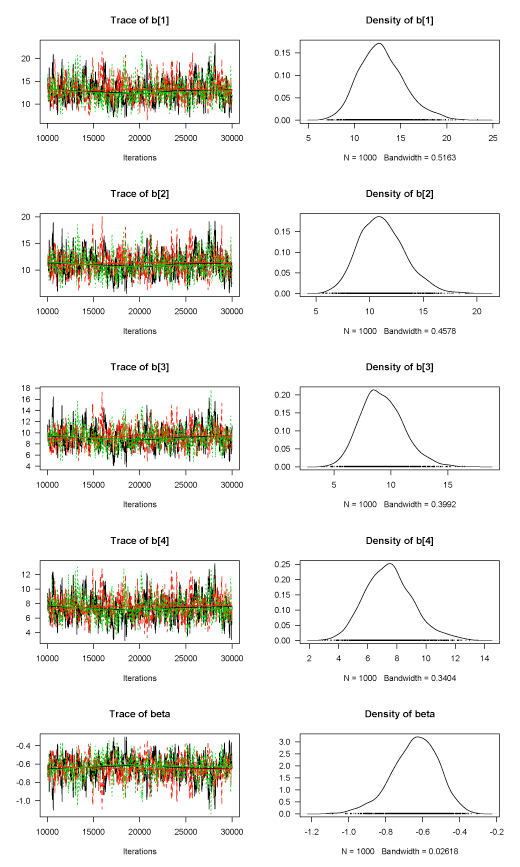
> summary(post)
Iterations = 10020:30000
Thinning interval = 20
Number of chains = 3
Sample size per chain = 1000
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
b[1] 12.9683 2.4547 0.044817 0.125126
b[2] 11.1690 2.1419 0.039106 0.106204
b[3] 9.2368 1.8719 0.034176 0.093751
b[4] 7.4827 1.6408 0.029957 0.080766
beta -0.6419 0.1248 0.002278 0.006412
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
b[1] 8.7051 11.2469 12.7851 14.4835 18.5234
b[2] 7.4140 9.6160 11.0205 12.5105 15.7387
b[3] 5.9469 7.9332 9.1046 10.4362 13.3192
b[4] 4.5627 6.3657 7.4074 8.5000 11.1831
beta -0.9143 -0.7195 -0.6339 -0.5554 -0.4202
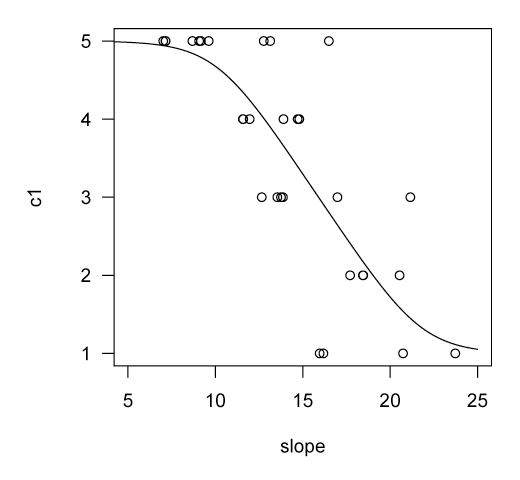
データに、期待値を重ねてみる。
predict.clm <- function(x, params) {
inv.logit <- function(x) exp(x) / (1 + exp(x))
b1 <- params[1]
b2 <- params[2]
b3 <- params[3]
b4 <- params[4]
beta <- params[5]
p5 <- inv.logit(beta * x + b4)
p4 <- inv.logit(beta * x + b3)
p3 <- inv.logit(beta * x + b2)
p2 <- inv.logit(beta * x + b1)
p1 <- 1
1 * (p1 - p2) +
2 * (p2 - p3) +
3 * (p3 - p4) +
4 * (p4 - p5) +
5 * p5
}
params <- summary(post)$statistics[,1]
x <- seq(0, 25, length = 100)
y <- predict.clm(x, params)
par(mai = c(1, 1, 0.25, 0.25))
plot(slope, c1, xlim = c(5, 25), las = 1)
lines(x, y, lty = 1, lwd = 1)




コメント 0