Stanで状態空間モデル [統計]
dlmその3のモデルをStanでやってみる。
statespace.stan
data {
int<lower=1> N;
real y[N];
int<lower=0, upper=1> x[N];
}
parameters {
real mu[N];
real mu0;
real lambda;
real<lower=0> sigma[2];
}
model {
for (t in 1:N) {
y[t] ~ normal(mu[t] + lambda * x[t], sigma[1]);
}
mu[1] ~ normal(mu0, sigma[2]);
for (t in 2:N) {
mu[t] ~ normal(mu[t - 1], sigma[2]);
}
}
RStanでは
data(Nile)
n <- length(Nile)
x <- c(rep(0, 27), rep(1, n - 27))
model.file <- "statespace.stan"
model <- stan_model(model.file)
seeds <- c(12, 123, 1234, 12345)
inits <- list(list(mu = rep(100, n), mu0 = 100,
lambda = -1000, sigma = c(1, 10)),
list(mu = rep(1000, n), mu0 = 1000,
lambda = -1, sigma = c(10, 10)),
list(mu = rep(500, n), mu0 = 500,
lambda = -10, sigma = c(100, 10)),
list(mu = rep(5000, n), mu0 = 5000,
lambda = -100, sigma = c(10, 10)))
fit.l <- mclapply(1:4,
function(i) {
sampling(model,
data = list(N = n,
y = as.vector(Nile),
x = x),
pars = c("mu", "lambda", "sigma"),
chains = 1, chain_id = i,
seed = seeds[i], init = inits[i],
iter = 21000, warmup = 1000, thin = 20)
}, mc.cores = 4)
fit <- sflist2stanfit(fit.l)
手もとのOS X MavericksではR.app上でmclapplyでrstanをつかうとうまくいかない。ESS上で実行した。
結果
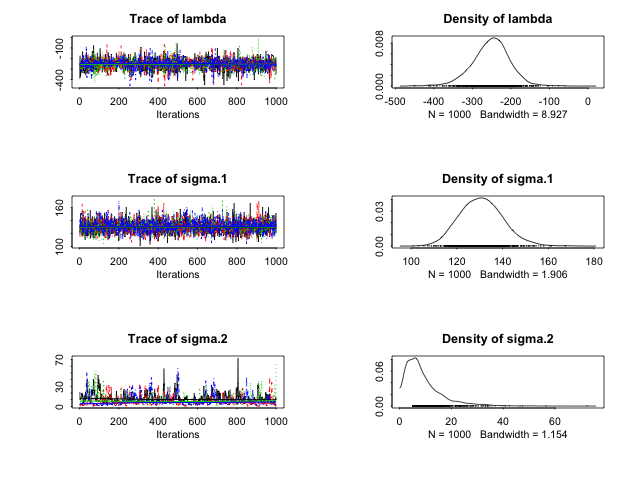
traceplot(fit, c("lambda", "sigma"), inc_warmup = FALSE)

状態モデルの値を実測値と重ねてみる。dlmの結果とくらべると分散が大きいのだがなぜだろうか。
s <- start(Nile)[1]
e <- end(Nile)[1]
fit.mean <- get_posterior_mean(fit)
loc.mu1 <- match("mu[1]", rownames(fit.mean))
mu <- fit.mean[loc.mu1:(loc.mu1 + e - s), "mean-all chains"]
lambda <- fit.mean["lambda", "mean-all chains"]
y <- mu + lambda * x
par(mai = c(1, 1, 0.5, 0.5))
plot(Nile, type ='o', las = 1)
lines(s:e, y, col = "blue", lwd = 2)

同様のことをコマンドラインからStanでやってみる。やはりこちらの方が高速。
./statespace sample num_samples=20000 num_warmup=1000 thin=20 id=1 \ data file="statespace.data.R" init="statespace.init1.R" \ output file="statespace.chain1.csv" refresh=2000 \ random seed=12 & ./statespace sample num_samples=20000 num_warmup=1000 thin=20 id=2 \ data file="statespace.data.R" init="statespace.init2.R" \ output file="statespace.chain2.csv" refresh=2000 \ random seed=123 & ./statespace sample num_samples=20000 num_warmup=1000 thin=20 id=3 \ data file="statespace.data.R" init="statespace.init3.R" \ output file="statespace.chain3.csv" refresh=2000 \ random seed=1234& ./statespace sample num_samples=20000 num_warmup=1000 thin=20 id=4 \ data file="statespace.data.R" init="statespace.init4.R" \ output file="statespace.chain4.csv" refresh=2000 \ random seed=12345
データと初期値はあらかじめファイルに書き出しておく。
結果
library(coda)
fit.l <- lapply(1:4, function(i) {
filename <- paste("statespace.chain", i, ".csv", sep = "")
samples <- read.csv(filename, comment = "#")
as.mcmc(samples)
})
fit <- as.mcmc.list(fit.l)
plot(fit[, c("lambda", "sigma.1", "sigma.2")])




コメント 0